
A machine that can perfectly understand and respond to human language has been the paradigm of success in artificial intelligence since Turing. The last decade has featured an ongoing revolution in language-focused machine learning, enabled primarily by new architectures and skyrocketing scale. A single model with billions of parameters, like OpenAI’s GPT-3, can complete a huge variety of tasks, from answering questions to generating text, based on few or even zero examples. Yet this revolution will not continue unhindered. I argue that large language models (LLMs) are structurally incapable of achieving human-level language abilities. By applying critical insights from cognitive science to deep learning, I develop both empirical and theoretical arguments to temper the overzealous excitement that LLMs will soon ‘solve’ natural language processing (NLP). There is more to language than LLMs can grasp. Finally, I sketch some more tractable pathways to language understanding by machines.
Crucially, my thesis is distinct from other long-standing and contentious debates in cognitive science. I do not defend the related but much more heavyweight assertions that artificial intelligence in general is impossible or that connectionism is false. Rather, I muster evidence against the specific approach of LLMs, showing that this method is extremely unlikely to match the human ability to understand and use language. These problems with LLMs are structural, and not merely incidental quirks of certain models or inadequacies due to insufficient scale or incomplete data. The issues stem from the constitutive features of LLMs, like applying statistical learning to text data.
Why should we care if LLMs can truly “think” or “understand”? Often, unarticulated fears and anxieties get entangled with this question – worries about our obsolescence as humans, of AI taking over our jobs and systems, of AI becoming sentient and evil, of being unable to keep up with our own creation. These are all fears worth exploring in their own right. Sometimes they are dismissed with a simple “oh, but it’s not really thinking.” This is not enough. We need to dig into these problems and their implications. But in this essay, I aim to bypass these fears somewhat by focusing on the structural and technical features of LLMs, and the philosophy and cognitive science of language understanding.
1. The Structure of Large Language Models (LLMs)
A language model (LM) is a system for predicting strings in a sequence. Formally, an LM is simply a probability distribution over a sequence of words. The model samples from this distribution to find the conditional probability of different words appearing in the sequence. Early research centered on N-gram LMs, which just use the relative frequency of words in the training data to predict what words come next. In contrast, LLMs are the state-of-the-art: models with (at least) millions of parameters that train an artificial neural network (ANN) to predict strings. Simply put, you can give an LLM a fragment of text, and it can tell you what is most likely to come next based on its statistical model of human language. Once the system gets good enough at predicting what comes next, it can generate new patterns of text that match the structure of its corpus.
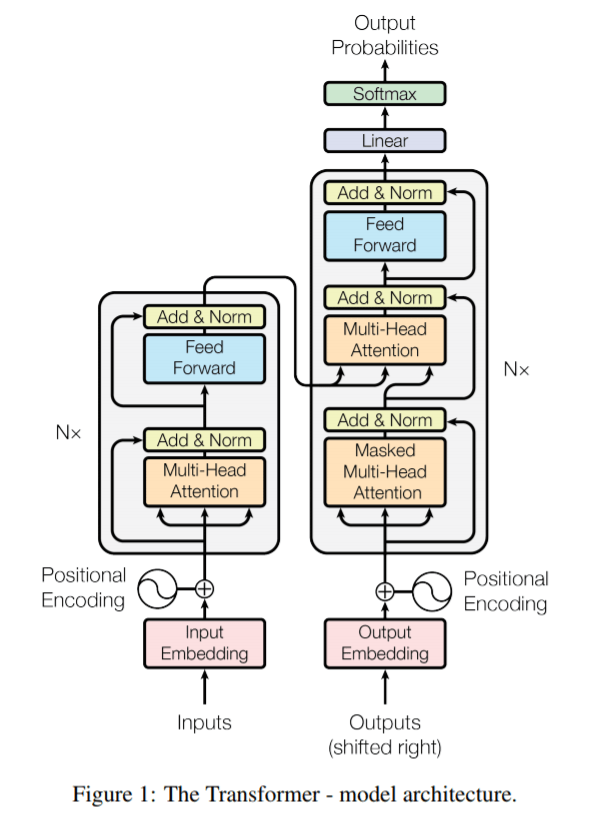
These models start by converting words to vectors (embeddings), where semantically similar words are closer together in the representational space. Then, they train an ANN to predict an output label (the next word in text) given some input vector (the context). Almost all modern LLMs involve transformers, an architecture that uses self-attention mechanisms to weight the significance of each word in the input and takes advantage of parallelization to process all the input data at once (Vaswani et al, 2017). Due to a perfect storm involving huge open-access databases of internet text, an outpouring of investments from tech giants, and faster compute with new cloud-based TPU and GPU processors, these LLMs have become the golden child of deep learning.
2. Evaluating language understanding
I asked GPT-NeoX, an open-source version of GPT, if LLMs have human-level language abilities.[1] Here are a some of the more coherent sentences from its response:
It is a complex task to define the human ability of language. As a community, we do not have a consensus…it is not a simple task to make an argument that the human ability of language is not contained in large NLP models.
– GPT-NeoX
I hold that this model is just unthinkingly reproducing patterns from its training data and that no LLM understands language. While limited tests can make LLMs seem successful, more thorough and extended imitation games will eventually betray the system’s inadequacy. Even Yeshua Bengio, one of the godfathers of deep learning, stated that the field “hasn’t delivered yet on systems that can discover high-level representations—the kind of concepts we use in language” (Saba, 2022). Just producing human-like text is not enough, as having human-level language abilities is a symptom of understanding extra-linguistic representations like concepts and situations.
How do we know if LMs have human-level language abilities? Current research relies on both intrinsic measures to calculate the LM’s theoretical accuracy, and extrinsic measures to evaluate the model’s performance on concrete tasks. These metrics illustrate both the successes and the blind spots of LLMs. Perplexity is one key entropy-based intrinsic measure for determining how well an LM predicts an unseen test set. Lower perplexity indicates higher predictive power and accuracy. A perplexity of 10-12 is considered human-level, and GPT-3 achieves a word-level perplexity of 20.5 (Shen et al, 2017). While this is an impressive result, it is still a long way from human performance – and it required a model with 175B parameters, 45TB of training data, and $12 million in compute costs (Wiggers, 2020). The most comprehensive benchmark for evaluating LMs on actual language tasks is SuperGLUE, a composite of many tests from reading comprehension to recognizing words in context to causal reasoning (Wang et al, 2020). GPT-3 achieved a total SuperGLUE score of 71.8%, where the human baseline is 89.8%. GPT-3 also reached an accuracy of 80.1% on the Winograd schema challenge, a difficult assessment that requires the model to reason about its world-knowledge to resolve an ambiguity in a statement (Levesque & Morgenstern, 2012). Are these remarkable empirical results enough to show that LLMs have already matched or exceeded human language abilities?
A closer analysis reveals serious flaws in these findings. LMs learn by finding co-occurrence patterns in the streams of symbols from the input data. LLMs trained on a huge corpus of internet text have almost certainly encountered sentences very similar to the test prompts. This is the duplication problem: testing a model on information it has already been exposed to, like giving a student an exam they have a cheat-sheet for or have practiced many times. Unlike humans, who can understand and reason about the underlying representations connected to words, GPT-3 just looks back on its many terabytes of training data to assess how often these tokens occur together. Therefore, LMs can simulate language comprehension, although more probing always reveals the lacuna of basic understanding behind this illusion. A LLM is like one of Searle’s Chinese rooms, except no philosophical arguments are needed to establish its blindness to meaning – it is enough to just understand the model and interact with it.

In fact, the creators of GPT-3 admit that the model has an “increased potential for contamination and memorization” (Brown et al, 2020, p. 7) because the tests are present in the training data. The authors tried to reduce this contamination by eliminating exact matches of the test cases from the input data. However, GPT-3 can still exhibit (illusory) high performance by exploiting similar patterns from the training data to answer questions, even if the exact answer is not present. Even more damning is the finding that the frequency of terms in an LLM’s input data is linearly correlated with its performance on related tests, suggesting these models mostly rely on memorization-like mechanisms (Razeghi et al, 2022). Other studies found that LLM performance can be fully “accounted for by exploitation of spurious statistical cues in the dataset” (Niven & Kao, 2019), and their accuracy results from employing heuristics that only work for frequent example types (McCoy et al, 2019). Thus, LLMs cannot make generalizable, novel, and robust linguistic inferences beyond statistical associations.

Viewing LLMs as sophisticated search engines that scan through their training data can help explain why they perform well on some tasks and fail on others. Many examples show that GPT-3 lacks conceptual understanding and has no idea what the words it uses mean. For instance, it fails to keep track of objects and characters in stories, thinks a swimsuit is appropriate attire for a courtroom when “clean” is in the sentence, states that grape juice is poison when “sick” appears nearby, and wanders into irrelevant nonsense in any response longer than a few sentences (Marcus and Davis, 2020). The original paper also shows that the model cannot infer basic logical relationships between two sentences and cannot do any math but simple arithmetic that can be memorized from tables in the training data (Brown et al, 2020). Further, the same tests used to assess human linguistic capabilities reveal the failures of LLMs. On an extensive set of psycholinguistic tests, BERT (a major LLM) struggles with pragmatic inferences, shows context insensitivity, cannot predict clearly implied events, fails to prefer true over false completions for sentences on category membership, and generally only succeeds when it can exploit loopholes in the training data (Ettinger, 2020). Whenever uniquely human language abilities are tested, LLMs malfunction.
Ultimately, this analysis shows that even the most advanced LLMs do not understand language. Further, their successes are only possible with the aid of a human intelligence to cue the model with well-designed prompts, collect enough relevant training data, and scan through the generations for appropriate responses. This makes LLMs a human-in-the-loop system, which cannot exhibit linguistic capabilities without a person to guide the model. LLMs may employ similar computational structures as human language, for as Futrell (2019) finds, the “behavior of neural language models reflects the kind of generalizations that a symbolic grammar-based description of language would capture” (p. 1). However, the fact that LLMs fail on unfamiliar or untrained prompts suggests that they use a simpler and more rigid grammar than human language, where “even slight changes may cause the [program] to fail” (Granger, 2020, p. 27). Larger models simply allow the LLM to hide its inability to understand for longer intervals. Of course, LLMs also lack a basic element of language – communicative intent. They do not express meaningful intentions or try to interact with their prompters, instead just babbling about what they are prompted to babble about, often in seemingly random and contradictory directions. Therefore, LLMs can be seen as a kind of sophisticated search engine that crawls over its input data for matches. They can memorize and recall but do not reason or understand.
2. Why LLMs will not understand language, and how other models could
Beyond this evidence on the limitations of current LLMs, more theoretical arguments show that this kind of system cannot reach human-level language understanding. Critics of connectionism have long argued that language relies upon an underlying “language of thought,” involving representations with systematicity and combinatorial structure (Fodor & Pylyshyn 1988; Fodor 1998). Although these are important considerations, my arguments do not depend on these claims and are targeted specifically at LLMs. The fundamental problem is that deep learning ignores a core finding of cognitive science: sophisticated use of language relies upon world models and abstract representations. Systems like LLMs, which train on text-only data and use statistical learning to predict words, cannot understand language for two key reasons: first, even with vast scale, their training and data do not have the required information; and second, LLMs lack the world-modeling and symbolic reasoning systems that underpin the most important aspects of human language.
The data that LLMs rely upon has a fundamental problem: it is entirely linguistic. All LMs receive are streams of symbols detached from their referents, and all they can do is find predictive patterns in those streams. But critically, understanding language requires having a grasp of the situation in the external world, representing other agents with their emotions and motivations, and connecting all of these factors to syntactic structures and semantic terms. Since LLMs rely solely on text data that is not grounded in any external or extra-linguistic representation, the models are stuck within the system of language, and thus cannot understand it. This is the symbol grounding problem: with access to just formal symbol system, one cannot figure out what these symbols are connected to outside the system (Harnad, 1990). Syntax alone is not enough to infer semantics. Training on just the form of language can allow LLMs to leverage artifacts in the data, but “cannot in principle lead to the learning of meaning” (Bender & Koller, 2020). Without any extralinguistic grounding, LLMs will inevitably misuse words, fail to pick up communicative intents, and misunderstand language.

Research on language acquisition shows that how children learn is strikingly different from the LLM training process. Infants learn language by drawing on a wide range of cues, while LMs only train on the tiny slice of the world in their input texts. When children are forced to use a more LLM-like learning process, limited to a single input modality and deprived of social interaction, they fail to learn language. For instance, Kuhl (2007) shows that infants quickly learned Mandarin words with live exposure to native speakers but learned almost nothing from TV or audio alone.
Further, statistical learning alone is not enough to ‘crack the speech code,’ as children need varied and frequent interactions with other agents in social situations to grasp the meanings of symbols (Kuhl, 2011). Indeed, it seems that a critical mechanism for language learning is joint attention, when a child and a teacher are focusing on the same thing and both aware of this (Baldwin & Moses, 1994). Recent research shows that how much babies follow other peoples’ gaze when speaking predicts their vocabulary comprehension 7-8 months later (Brooks & Meltzoff, 2005). Language is a system for communicating intents to real people in the real world, and the lexical similarity and syntactic structure of raw text are not enough to learn this system. LLMs are missing some key aspects of human language: these models are not part of a linguistic community, they have no perception or model of the world beyond language, they do not act as agents or express intentions, and they do not form beliefs about propositions. (At least as far as we know – and given their structure, attributing mental properties like beliefs and intentions to LLMs is not warranted unless we have very strong evidence to do so).
In defense of LLMs, some argue for the scaling hypothesis, the idea that high-level abilities like language can arise just by increasing the number of basic computational elements. As Granger (2020) argues, intelligence may be mostly a product of allometric scaling of brain size, and “human-unique and ubiquitous abilities, very much including language, arise as a (huge and crucial) qualitative difference originating from a (colossal) quantitative change” (32). Indeed, the performance of neural LLMs has scaled in a power-law relationship with model size, data size, and the amount of compute used for training (Kaplan et al, 2020). However, I do not need to dispute this hypothesis. It may be the case that sheer scale – the right quantity of the right kind of basic computational elements – is sufficient for human-level language understanding, but the kind of scale and the type of circuitry involved in LLMs will not singlehandedly achieve this milestone. Further, LLMs already have enormous scale—the recent Megatron-Turing model has 530 billion parameters and took the equivalent of 1558 trans-American flights in energy costs for training (Simon, 2021). Human babies access enormous amounts of high-definition data in many modalities, and LLMs cannot match either the quality or quantity of this information. How many more resources do we need to throw into scaling before we realize the LLM approach will not achieve full language understanding?
3. Conclusions and alternate approaches
Machine language understanding is still possible in principle, even if this popular current approach is a dead end. For example, deep learning could take inspiration from the 4E framework for cognition: to reach human-level understanding, machines must be embodied, embedded, enactive, and extended (Borghi et al, 2013). One way to implement this approach would be to integrate an LLM as just one module in a larger system, like a robotic agent in a reinforcement-learning environment. The agent could use the LLM’s powerful text processing capabilities as needed but could also use other modules to process different sensory modalities, interact with other agents, and take actions. By embedding the agent in a more real environment, it may over time learn how to elicit all of these sub-systems for the optimal behavior – potentially including language understanding. Building up a model of the world could allow the agent could connect the word embeddings from the LLM to external referents like objects and actions. Thus, embodied cognition could be fruitful approach to solving the grounding problem for machine language understanding.

Another approach argues that LLMs only need to be augmented with modules for symbolic reasoning and world modeling. Advocates for this approach argue that LLMs function like the System 1 of human cognition, performing fast, heuristic, but often flawed inferences, and just need to be supplemented with a more deliberative System 2 module. This System 2 could represent and update world knowledge with hierarchical Bayesian modeling, a promising approach to cognition (Tenenbaum et al, 2011). As human children seem to use built-in templates like intuitive psychology and physics to learn, these models will likely need to be preprogrammed with some basic theories informed by scientific research (Lake et al, 2017). For instance, one MIT team combined GPT-3 with a symbolic world state model to dramatically improve the coherence of the LLM’s text generation (Nye et al, 2021). These neuro-symbolic systems can harness the power of deep learning while rectifying its shortcomings.
Conclusively, LLMs alone cannot solve language. However, I may be wrong about this. It is risky to be an AI skeptic, as many naysayers have already been proven wrong. This paper does not make an unfalsifiable philosophical argument, but a prediction about the future of AI. Larger LMs will be highly impactful, but banal. These models may allow us to automate many routine linguistic tasks, but will not understand language or be “smart” in a way current LLMs are not. If it turns out LLMs can reach human-level language abilities, this will teach us a great deal, indicating that we can learn everything for language understanding by simply training on text data. Progress on LLMs can inform our theory of language, and psychology and linguistics should inform the development of LLMs. This interdisciplinary process is our best hope of instilling human language understanding in machines.
Appendix: The Aftermath of ChatGPT
I wrote this essay before ChatGPT was released and GPT-3 was improved with the new text-davinci-003 model. I stand by the arguments here, but of course I’ve updated my thinking after the undeniably incredible performance of GPT-3. It has achieved extraordinary capabilities with a lot of scale and tons of compute. However, as Murray Shanahan writes in the excellent paper Talking About Large Language Models:
“It doesn’t matter what internal mechanisms it uses, a sequence predictor is not, in itself, the kind of thing that could, even in principle, have communicative intent, and simply embedding it in a dialogue management system will not help. We know that the internal mechanisms of LLMs are not sensitive to things like the truth of the word sequences it predicts. It does not refer to any external “ground” for evaluating the meaning of these words.”
– Shanahn, Talking About Large Language Models, page 5.
One of the key points here is that humans can make a causal connection between words and phenomena in the real world. On the other hand, LLMs can only make a correlation between words and other words. For instance, when you ask ChatGPT “what country is to the east of Yemen,” it will answer correctly – “Oman.” However, this is not because it has built a sophisticated model of the geography of the world, or because it has developed the belief that Oman is east of Yemen. Rather, it’s just that tokens like ‘Yemen,’ ‘east,’ and ‘Oman’ were paired the most frequently in that order and context in ChatGPT’s text corpus. The model answers this question in the same way it would answer the prompt “twinkle twinkle” with “little star.” Both are simply correlation-based statistical predictions. To a human, these are two distinct types of question. One is about the real world, and one is simply pairing some text with the most likely completion. To an LLM, they’re not different.
These correlations are accurate enough that ChatGPT is almost always right. But there are hundreds of examples where the model simply confabulates, hallucinates, or otherwise bullshits the answer. It cannot think from first principles, make epistemic judgements based on experience, or compare its beliefs to a model of the world. This is why its text-based educated guessing of what word should come text become unhinged from reality. Language is learned by talking to other language-users while immersed in a shared world and engaged in joint activity. Without this, the LLM cannot develop human-level language abilities. One of the most dangerous abilities of ChatGPT is its ability to make up plausible-sounding bullshit, that looks right but is in fact wrong – for example, coming up with fake info security answers, or creating regex answers with subtle flaws.
However, it might be the case that LLMs alone can achieve language understanding. It is possible that in the process of trying to perform sequence prediction, the LLM stumbled upon emergent mechanisms that warrant higher-level descriptions like “knowledge,” “belief,” or “understanding.” Perhaps in all of this large-scale statistical learning, the LLM discovered that it could predict tokens better if it also represented the connections between words and stored a latent representation of the world described by these words. Maybe all that is needed to understand human language is contained within language itself. In other words, maybe human language is reducible to next token prediction. If we create a performant enough LLM with enough training data, it will be able to perfectly simulate language understanding. This essay argues that this outcome is unlikely for structural reasons. But it is still possible – we have been shocked by AI research before.
How can we tell if an LLM really does understand? There is no way to prove its ability to understand human language, as even millions of successful examples where it seems to understand could be disproven by a single edge case where it clearly does not understand. ChatGPT can clearly pass something like the Turing Test in most cases, but it fails (showing its true colors as an AI) in some other cases. What success rate is enough to justify calling it “understanding”? These are all important questions, and the answers are still unclear.
Works Cited
Granger, R. (2020). Toward the quantification of cognition. arXiv preprint arXiv:2008.05580.
Borghi, A. M., Scorolli, C., Caligiore, D., Baldassarre, G., & Tummolini, L. (2013). The embodied mind extended: using words as social tools. Frontiers in psychology, 4, 214.
Nye, M., Tessler, M., Tenenbaum, J., & Lake, B. M. (2021). Improving coherence and consistency in neural sequence models with dual-system, neuro-symbolic reasoning. Advances in Neural Information Processing Systems, 34.
Tenenbaum, J. B., Kemp, C., Griffiths, T. L., & Goodman, N. D. (2011). How to grow a mind: Statistics, structure, and abstraction. Science, 331(6022), 1279-1285.
Lake, B. M., Ullman, T. D., Tenenbaum, J. B., & Gershman, S. J. (2017). Building machines that learn and think like people. Behavioral and brain sciences, 40.
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … & Polosukhin, I. (2017). Attention is all you need. Advances in neural information processing systems, 30.
Bender, E. M., & Koller, A. (2020, July). Climbing towards NLU: On meaning, form, and understanding in the age of data. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (pp. 5185-5198).
Harnad, S. (1990). The symbol grounding problem. Physica D: Nonlinear Phenomena, 42(1-3), 335-346.
Kaplan, J., McCandlish, S., Henighan, T., Brown, T. B., Chess, B., Child, R., … & Amodei, D. (2020). Scaling laws for neural language models. arXiv preprint arXiv:2001.08361.
Kuhl, P. K. (2011). Early language learning and literacy: neuroscience implications for education. Mind, brain, and education, 5(3), 128-142.
Kuhl, P. K. (2007). Is speech learning ‘gated’ by the social brain?. Developmental science, 10(1), 110-120.
Baldwin, D. A., & Moses, L. J. (1994). Early understanding of referential intent and attentional focus: Evidence from language and emotion. Children’s early understanding of mind: Origins and development, 133-156.
Ettinger, A. (2020). What BERT is not: Lessons from a new suite of psycholinguistic diagnostics for language models. Transactions of the Association for Computational Linguistics, 8, 34-48.
Minsky, M. L. (1974) A framework for representing knowledge. MIT-AI Laboratory Memo 306. [aBML]
Marcus, Gary and Davis, Ernest. (2020). GPT-3, Bloviator: OpenAI’s language generator has no idea what it’s talking about. MIT Technology Review. https://www.technologyreview.com/2020/08/22/1007539/gpt3-openai-language-generator-artificial-intelligence-ai-opinion/
Futrell, R., Wilcox, E., Morita, T., Qian, P., Ballesteros, M., & Levy, R. (2019). Neural language models as psycholinguistic subjects: Representations of syntactic state. arXiv preprint arXiv:1903.03260.
Fodor, J. A., & Pylyshyn, Z. W. (1988). Connectionism and cognitive architecture: A critical analysis. Cognition, 28(1-2), 3-71.
Fodor, J. A. (1998). Concepts: Where cognitive science went wrong. Oxford University Press.
Saba, Walid (2022). AI Cannot Ignore Symbolic Logic, and Here’s Why. ONTOLOGIK on Medium. https://medium.com/ontologik/ai-cannot-ignore-symbolic-logic-and-heres-why-1f896713525b
Shanahan, M. (2022). Talking About Large Language Models. arXiv preprint arXiv:2212.03551.
Shen, X., Oualil, Y., Greenberg, C., Singh, M., & Klakow, D. (2017). Estimation of Gap Between Current Language Models and Human Performance. In INTERSPEECH (pp. 553-557).
Simon, Julien (2021). Large Language Models: A New Moore’s Law? HuggingFace. https://huggingface.co/blog/large-language-models
Wiggers, K. (2020). OpenAI’s massive GPT-3 model is impressive, but size isn’t everything. VentureBeat.com. https://venturebeat.com/2020/06/01/ai-machine-learning-openai-gpt-3-size-isnt-everything/
Wang, A., Pruksachatkun, Y., Nangia, N., Singh, A., Michael, J., Hill, F., … & Bowman, S. (2019). Superglue: A stickier benchmark for general-purpose language understanding systems. Advances in neural information processing systems, 32.
Razeghi, Y., Logan IV, R. L., Gardner, M., & Singh, S. (2022). Impact of pretraining term frequencies on few-shot reasoning. arXiv preprint arXiv:2202.0720
Black, S., Biderman, S., Hallahan, E., Anthony, Q., Gao, L., Golding, L., … & Weinbach, S. (2022). Gpt-neox-20b: An open-source autoregressive language model. arXiv preprint arXiv:2204.06745. ↑